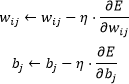|
|
 |
 |
| ���ɂ����鐶��AI�Ɖ摜�F��AI�̊��p���� |
|
| �x��@�ĕ� |
�i��Ёj���V�X�e������u�t�c |
�i�������@2024�N11�����j |
|
|
�@�{�e�́A���Ǘ��Ɩ��ɂ�����AI�Z�p�̊��p�\����T�邽�߁A����AI����щ摜�F��AI�̊�{�Z�p�Ƃ��̓K�p������l�@�������̂ł���B���ɁA���̌��o���f���ł���YOLOv8��p���ď����̃o���u�����o����������s���A���̌��ʂ����B�܂��A�t�@�C���`���[�j���O��f�[�^�g���Ȃǂ̋Z�p�I��@�ɂ��Ă��ڍׂɐ������A���ƊE�ɂ�����AI�����̌��ʂƉۑ�𖾂炩�ɂ����B����AAI�Z�p�����Ǘ��Ɩ��ɗ^����e���Ƃ��̓W�]�ɂ��Ă��q�ׂ�B
�@Key Words: ���A����AI�AChatGPT�A�摜�F���A���̌��o�AYOLO�A�t�@�C���`���[�j���O |
|
|
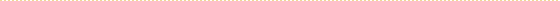 |
|
�P�D�͂��߂�
�i1�j���߂�AI�ɂ���
�@�{�e�́A2024�N8��14������15���ɂ����Ď��M���ꂽ���̂ł���B�`���ɉ��̂��̂悤�Ȃ��Ƃ����������Ƃ����ƁAAI�Z�p�͂܂���“���i����”�Ńg�����h���ω��������Ă���A�{�e�Ř_����Z�p��T�[�r�X�̓��e�͎��M���_�̂��̂ł��邱�Ƃ��������Ă����B���p���ꂽ���͕ς��Ȃ����A�T�[�r�X��d�l�̕ύX������\�������邽�߁A���̓_�ɗ��ӂ������������B
�@���āA2022�N��AI�Z�p�̑傫�ȓ]���_�ƂȂ����N�ł���A�uMidjourney�v��uStable Diffusion�v�Ƃ������摜����AI�Ɏn�܂�A�uChatGPT�v�ɑ�\������K�͌��ꃂ�f�� (LLM)��p����AI�T�[�r�X�����[���`���ꂽ�B����AI�Z�p�E�T�[�r�X�͋}���ɕ��y���A�����̊�Ƃ������̋Z�p�̊��p���@��͍����A�r�W�l�X�̉�����ڎw���Ă���B
�@���ɁuChatGPT�v�Ȃǂ�LLM�́A���R���ꏈ���̕���Ŋv���I�ȉe����^���A�`���b�g�`����AI�T�[�r�X���}���ɍL�܂����B�����O�̊�Ƃ����̕���ɂ����ĐϋɓI�ɊJ����i�߂Ă���A�uChatGPT�v (OpenA) �A�uGemini�v (Google) ��A�uLlama�v (Meta) �ɑ�\�����I�[�v���\�[�X��LLM�����������݂���B
 |
| �}1�@ChatGPT��API�����̕ϑJ |
�@�T�[�r�X���p����API�̗����̒ቺ���A�e��Ƃ����ЃT�[�r�X��AI���������ƂȂ��Ă���B�Ⴆ�uChatGPT�v�͖����ŗ��p�\�ł��邾���łȂ��A�l���x���ŃJ�X�^�}�C�Y���ꂽ�uGPTs�v�Ƃ����`���b�g�@�\������Ă���B����ɁAAPI ��1) ���p�������A�b�v�f�[�g�̂��тɈ����ɂȂ��Ă���A�ŏ����ɔ�ׂă��f�����\�����サ�Ă���ɂ��ւ�炸�A�����͂��悻�\���̈�ɂ܂Œቺ���� (�}1) �B
�@�������Ȃ���A���{�ł�AI���p���͊e���Ɣ�r���ĈˑR�Ƃ��ĒႢ����ł���B�����Ȃ̃A���P�[�g���� 2) �ɂ��ƁA�l���p�i�u�g���Ă���i�ߋ��g�������Ƃ�����j�v�j�̊�����9.1%�ɉ߂����A���� (56.3%) �A�č� (46.3%) �A�p�� (39.8%) �A�h�C�c (34.6%) �Ɣ�ׂđ傫�ȊJ��������B�܂��A��Ƃ̗��p���ɂ����Ă��A“���p������j���߂Ă���”�i�u�ϋɓI�Ɋ��p������j�ł���v�A�u���p����̈�����肵�ė��p������j�ł���v�̍��v�j�Ɖ�����Ƃ͓��{�ł�42.7%�ɂƂǂ܂�A�č��A�h�C�c�A������80%�ȏ�̊�Ƃ����l�̕��j�������Ă��邱�ƂƔ�r���āA�Ⴂ�����ɂ���B
�i2�j���ɂ�����AI�̌���
�@���␅�����̕���ł�AI�Z�p�̗��p���i��ł���A�ߔN�̓��{�����w��ł́AAI�Ɋւ��錤�����\�Ⴆ�� 3), 4) �������s���Ă���B�܂��������W��ł�IoT�̍X�Ȃ锭�W�Ƃ���AI���p���������锭�\ 5)���������B�������A�����_�Ŏ��ۂ̃T�[�r�X�Ƃ��ď��Ǘ���AI����������Ă��鎖��͑��ƊE�Ɣ�ׂ�Ƃ܂����Ȃ��A���y�ɂ͎��Ԃ�v����ƍl������B
�@����ŁA����̋Z�p�v�V��AI���p�͕K�R�I�ł���A�ێ��Ǘ��⎩������iIoT�A�f�W�^���c�C���j�̕����AI�Z�p�̓������i�ނ��ƂŁA���Ǘ��Ɩ��ւ�AI�Z�������҂����B
�@�����ŁA�{�e�ł�AI�i����AI�y�щ摜�F��AI�j�̊�b�m���ɐG��A���ɂ�����AI�Z�p���p�̉\���ɂ��Ę_����B |
|
�Q�D����AI�ɂ���
�i1�j���߂̐���AI�̗���
a)�@�T�v
�@����AI�́A2022�N����}���ɐi���𐋂��A�����̃��[�U���l�����Ă���B���ɁuChatGPT�v (OpenAI) ��uGemini�v (Google) �A�uClaude�v (Anthoropic) �Ȃǂ̃T�[�r�X�́A���p�҂ɍ����]�����Ă���A�ŋ߂ł͎��R���ꐶ���̕��삾���łȂ��A�摜�≹�����܂߂��}���`���[�_��AI�ւ̊��҂Ƃ��ďd�v�Ȗ������ʂ����Ă���B2023�N�́w����AI���N�x�ƌĂ�ALLM�i��K�͌��ꃂ�f���j�̊J���������������钆�A�����̃��f���́A2022�N�Ɣ�r���Đ��\���啝�Ɍ��サ�A�����܂��͒�R�X�g�ŗ��p�ł���悤�ɂȂ��Ă���B
�@API�����̒ቺ���A����AI�̕��y���㉟�����Ă���B2023�N�ɂ�����API�T�[�r�X�̊J�������AGPT-3.5�̗��p�����͍��z�ł��������A���݂ł͍ŐV���f���ł���GPT-4o��GPT-4o mini�̗��p�������啝�Ɉ����������Ă���B�܂��A���p�\�ȃg�[�N�� ��2) �����啝�ɑ������Ă���A�ȑO�͂��������Ɍ����Ă����g�[�N���������݂ł͔���I�ɑ��債�A��葽���̃f�[�^�������ł���悤�ɂȂ����B����ɂ��A����AI�̊��p�͈͂�����ɍL�������Ƃ�����B
�@���̂悤�Ȑ���AI�̐i���̔w�i�ɂ́A�j���[�����l�b�g���[�N�̔��W������B���ɁuAttention Is All You Need 6)�v�Ŕ��\���ꂽ�uTransformer�v�Z�p�́A����AI�̔��ɂ����ďd�v�Ȗ������ʂ����Ă���B���̋Z�p�́A�]���̃��J�����g�j���[�����l�b�g���[�N�iRNN�j�̉ۑ���������A���R���ꏈ�����܂ޑ����̕���ő傫�ȉe����^�����B
�@���������Ă��̏͂ł́A�j���[�����l�b�g���[�N��RNN�̊�{�Z�p�ɐG��Atransformer�ւ̔��W�A������ChatGPT�̎g������RAG�Z�p�ɂ��Ę_����B
b)�@�j���[�����l�b�g���[�N��b
�@�j���[�����l�b�g���[�N�́A����̋@�B�w�K�Z�p�̍������Ȃ����f���ł���A���̍\���͐l�Ԃ̔]�̐_�o��H��͕킵�����̂ł���B�j���[�����l�b�g���[�N�́A���͑w�A�B��w�i���ԑw�j�A����яo�͑w����\������A�e�w�̃j���[�������O�̑w�̃j���[�����ƌ��т��Ă���B���̌��т��́u�d�݁iweights�j�v�ƌĂ�A�w�K�ߒ��Œ��������B
�@�ȉ����ȒP�Ƀf�[�^�`�B�̃v���Z�X���������B
�@���̓f�[�^x�͓��͑w�ɋ�������A�e�w�̃j���[�����������ʉ߂��Ă����B�e�j���[����j�ɂ����āA�O�̑w�̃j���[����i����̓��͂́A�d��wij���|�����킹�ē`�B����A����Ƀo�C�A�X��bj�����Z�����B���̑����͎͂��̂悤�ɕ\�����B
�@���̑�����zj�ɑ��āA�������� (Activation Function) ���K�p����A�o��aj�����肳���B
�@��ʓI�Ȋ��������Ƃ��ẮA�V�O���C�h����ReLU (Rectified Linear Unit) �����g�p�����B�Ⴆ�AReLU���͈ȉ��̂悤�ɒ�`�����B
�@���̃v���Z�X���B��w����o�͑w�܂ŌJ��Ԃ���A�ŏI�I�ɏo�͑w�œ�����o�͂��j���[�����l�b�g���[�N�̗\�����ʂƂȂ�B
�@���Ɋw�K�t�F�[�Y�ɂ�����t�`�d�̃t���[�ɂ��Đ�������B
�@�j���[�����l�b�g���[�N�̊w�K�́A�덷�t�`�d�@(Backpropagation) ��p���čs����B�܂��A�o�͑w�œ���ꂽ�\�����ʂƎ��ۂ̃��x���Ƃ̌덷���v�Z���A���̌덷����ɏd�݂ƃo�C�A�X���X�V����B�덷���i�������j�Ƃ��ẮA�Ⴆ�Γ��덷�iMean Squared Error�j���悭�p������B
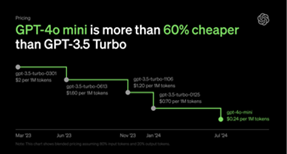
�@�����ŁAyi�͎��ۂ̒l�A �͗\���l�ł���B���̌덷E���ŏ������邽�߂ɁA���z�~���@�iGradient Descent�j��p���ďd��wij�ƃo�C�A�Xbj���X�V����B���Ȃ킿�A�d�݂ƃo�C�A�X�̍X�V�́A�w�K��η��p���Ď��̂悤�ɍs����B �͗\���l�ł���B���̌덷E���ŏ������邽�߂ɁA���z�~���@�iGradient Descent�j��p���ďd��wij�ƃo�C�A�Xbj���X�V����B���Ȃ킿�A�d�݂ƃo�C�A�X�̍X�V�́A�w�K��η��p���Ď��̂悤�ɍs����B
�@���̃v���Z�X���j���[�����l�b�g���[�N�̑S�w�ŌJ��Ԃ��A�덷���ŏ��������܂Ŋw�K���i�ށB
c)�@RNN�̊�b
�@RNN�i���J�����g�j���[�����l�b�g���[�N�j�́A�V�[�P���X�f�[�^�⎞�n��f�[�^���������邽�߂ɐv���ꂽ�j���[�����l�b�g���[�N�̈��ł���BRNN�̓����́A�B��w�̏o�͂����̃^�C���X�e�b�v�̓��͂Ƃ��čė��p����郊�J�����g�\���ɂ���B����ɂ��ARNN�͎��ԓI�Ȉˑ��W���l�����Ȃ���f�[�^�������ł���B
�@�ȉ���RNN�̍\���Ɠ�����ȒP�ɐ�������B
�@RNN�ł́A�e�^�C���X�e�b�vt�ɂ����āA����xt�ƑO�̃^�C���X�e�b�v�̉B����ht-1����������A���݂̉B����ht���v�Z�����B����ɂ��A�ߋ��̏�L������A���̃X�e�b�v�ɓ`�B�����B
�@RNN�̉B����ht�͈ȉ��̎��Ōv�Z�����B
�@�����ŁAWh��Uh�͏d�ݍs��Abh�̓o�C�A�X�Aσ�͊��������ł���B
�@�o��yt�́A�B����ht��p���Ď��̂悤�Ɍv�Z�����B
�@�ȏ�̒ʂ�ARNN�͎��ԓI�Ȉˑ��W�����f��������\�͂������A�����ˑ����̖���v�Z�����̒Ⴓ�Ƃ������ۑ肪���݂���B
�@�����ˑ����̖��Ƃ́ARNN�������V�[�P���X�ɂ����āA�ߋ��̏����\���ɕێ��ł��Ȃ����Ƃ��w���B���̖��́A���z������� (Vanishing Gradient Problem) �Ƃ��Ēm���A�l�b�g���[�N���[���Ȃ�ɂ�āA���z���������A�w�K������ɂȂ邱�ƂŔ�������B�܂��A�v�Z�����̒Ⴓ��RNN�̉ۑ�ł���BRNN�́A�V�[�P���X�𒀎��������邽�߁A����������ł���A���ɒ����V�[�P���X�ɑ��Ă͌v�Z���Ԃ����傷��B���̂��߁A��K�͂ȃf�[�^�Z�b�g��A���^�C�������ɂ͕s�����ł���B
�@�����̉ۑ���������邽�߂ɁA�V�����A�[�L�e�N�`���Ƃ��ĊJ�����ꂽ�̂��uTransformer�v�ł���B
d)�@Transformer�Z�p�̔w�i
�@ransformer�́ARNN�̎������ˑ����̖���v�Z�����̒Ⴓ���������邽�߂ɊJ�����ꂽ�v�V�I�ȋZ�p�ł���BTransformer�́A���Ȓ��Ӌ@�\�iSelf-Attention Mechanism�j�𒆐S�Ƃ����A�[�L�e�N�`�������Ă���A����ɂ��V�[�P���X�S�̂����ɏ������邱�Ƃ��\�ƂȂ����B����ɂ��A�e�v�f�Ԃ̊W���������I�ɑ����ARNN�Ɉˑ������Ƃ������x�ȃV�[�P���X�����������ł���悤�ɂȂ����B
�@���Ȓ��Ӌ@�\ (Self-Attention Mechanism�j �Ƃ́A�V�[�P���X���̊e�v�f�����̗v�f�Ƃǂ̂悤�Ɋ֘A���Ă��邩���v�Z���A�d�v�x�f���郁�J�j�Y���ł���B����ɂ��ATransformer�͒����ˑ��������ʓI�ɑ����邱�Ƃ��ł��A�V�[�P���X�S�̂���x�ɏ������邽�߁A�v�Z����������I�Ɍ��サ���B
�@Transformer�̓o��ɂ��A���R���ꏈ���ɂ�����LLM�̐��\�����I�Ɍ��サ�A���ʂƂ��Đ���AI�����܂��܂ȕ���Ŋ��p�����悤�ɂȂ����B�]����RNN�ɑ����āATransformer�͎��R���ꏈ���̃f�t�@�N�g�X�^���_�[�h�ƂȂ�A���݂̐���AI�Z�p�̊�Ղ��`�����Ă���B
�@���߂ł́ALLM�T�[�r�X�̃��C���X�g���[���ł���uChatGPT�v�𒆐S�ɁA���̗��p���@�ɂ��Ă���ɏڂ����q�ׂ�B
�i2�jChatGPT��RAG�ɂ���
a) ChatGPT�ɂ���
�@�ŋ߂�ChatGPT�́A�����łł����Ă��摜������PDF�t�@�C���̕��́A�uCode Interpreter�v�ƌĂ��v���O���~���O��p������͂��\�ł���ȂǁA���l�ȋ@�\����Ă���B���Ƀt�@�C���Y�t�@�\���lj�����Ĉȗ��A���p�҂̊��p�V�[�����啝�Ɋg�債�Ă���B
�@�Ⴆ�APDF�Y�t�ɂ����e�v��⎿�^�����A�摜�Y�t�ɂ��摜���́iGPT-4 Vision�j�́A�r�W�l�X�⌤���̌���Ŕ��ɗL�p�ł���B�܂��A�uCode Interpreter�v�ɂ��R�[�f�B���O�����Z�p���A�f�[�^���͂⎩�����^�X�N�ɂ����ċ��͂ȃc�[���ƂȂ��Ă���B
�@�����̋@�\�lj��ɂ��AGPT-4o�̂悤�ȍ��@�\LLM�́A�e�L�X�g�����łȂ��A�摜�≹�����������ł���u�}���`���[�_��AI�v�Ƃ��Ă̊��҂����܂�A���L�͂Ŕėp���̍������f���ւ̐i�����\�z�����B
�@�܂��ALLM�̊J�����i�ނɂ�āA�e�Ђ͎��g�̃h���C���m���\��������邱�Ƃ����d�v�ƂȂ��Ă���B���݂̃g�����h�̈�Ƃ��āA�uRAG�v (Retrieval-Augmented Generation) ������A���̋Z�p�����p���������̌������i�s���Ă���B
b) RAG�ɂ���
�@�uRAG�v (Retrieval-Augmented Generation) �́ALLM�ɊO���f�[�^����荞�݁A��������ɐ������ʂ�⊮����Z�p�ł���B���Ѓf�[�^���uChatGPT�v�Ȃǂ�LLM�Ŋ��p����ۂɁARAG�Z�p���L���ƂȂ�B
�@��̓I�ɂ́ARAG�͑傫���u�x�N�g���f�[�^���iembedding���j�v�A�u�����v�A�u�����v��3�̃X�e�b�v�ō\������Ă���BRAG�𗘗p���邱�ƂŁAAI���f���Ɋw�K�O�f�[�^��^���A��������A���^�C���ŗ��p���邱�Ƃ��\�ƂȂ�A�]���̃t�@�C���`���[�j���O��v�����v�g�G���W�j�A�����O�ɔ�ׁA�����I���R�X�g���ʂ̍�����@�ƂȂ��Ă���B
�@ChatGPT�ɂ����Ă��ARAG�Z�p�����p���邱�Ƃ��\�ł���A�Ⴆ��PDF�⎩�Ѓf�[�^��AI�ɒm���Ƃ��Ē��APoC (Proof of Concept) ��3) ��v���ɐi�߂邱�Ƃ��ł���B���̂悤�ȋZ�p�����p���邱�ƂŁA��Ƃ͂��_���AI���E�^�p�ł���悤�ɂȂ�B
�i3�j���ێ��Ǘ��v�̏����g����RAG�̌���
�@�{�͂ɂ����錋�ʂɂ����āA�y�[�W�̊W�シ�ׂĂ��L�ڂ��邱�Ƃ�������߁A�ȉ���URL��������QR�R�[�h�i�}2�j���Q�Ƃ��Ă������������B
�@�܂�ChatGPT�̐��\�̊m�F�̂��߂Ɉȉ��̃v�����v�g����͂��Ă݂�B
�@�u���n�艤�^�̈ێ��Ǘ��ŋC��t���邱�Ƃ́H�v
�@����Ə��������͐������@��S�ʂł�����悤�Ȉ�ʓI�ȉ��Ԃ��Ă����B�����ChatGPT�����n�艤�^�̏ڍׂ��w�K���Ă��炸�A�m���I�Ȑ����o�������ʂɋN������B����Ė{�͂ł͂��̉��x�����߂邱�Ƃ�ڕW�Ƃ���B
�@���āARAG�����Ɍ����ẮA�O�߂Ř_�����悤�Ɂu�x�N�g���f�[�^���iembedding���j�v���ŏ��̃X�e�b�v�Ƃ��čl������B��������쐬���ꂽ�x�N�g���f�[�^�̓x�N�g��DB�Ȃǂ̃f�[�^�x�[�X�ɕۑ�����A���[�U�̃N�G���ɑ���cos�ގ��x ��4) �Ȃǂ��g���āA�ގ��̕��͂���������t���[���Ƃ�B
�@�������A�����ł͎������ȕւɂ��邽�߁AChatGPT�̕W���@�\�ł���t�@�C���Y�t�@�\��p���āA�Y�t���ꂽ�h�L�������g�̒m������������ChatGPT�ɕԓ����Ă��炤�B
�@�Y�t���@�͂ƂĂ��ȒP�ŁA�`���b�g���Ƀh�L�������g�t�@�C�����h���b�O���h���b�v���邩�A�N���b�v�{�^���������ăG�N�X�v���[���[����ɂ�莩�g�̃t�@�C����I�����邱�ƂœY�t���邱�Ƃ��ł���B
�@����Y�t����t�@�C���̓j�b�R�[���i�ł���u���n�艤�^�v�y�сu���^�v�̈ێ��Ǘ��v�̏��Ƃ���B�Ȃ��A�{�h�L�������g�ɂ����Ă̓j�b�R�[������Ђ�HP 6) ���Q�Ƃ��ꂽ���B
�@�t�@�C���̃A�b�v���[�h���I������玟�Ƀ`���b�g���Ɏ����ɂ��ĕ����������Ƃ���͂���B�����ł͂قǂ̃v�����v�g�ɉ����āA���^�̏����܂߂��v�����v�g��p�ӂ����B
�@�u���n�艤�^�̈ێ��Ǘ��ŋC��t���邱�Ƃ́H�v
�@�u���n�艤�Ə��̗e�ʂ̈Ⴂ�������āv
�@�O�҂̌��ʂœ��M���ׂ��́A�Ɂu��1�ڐG���C���v�Ȃǐ��n�艤�^���L�̒P�ꂪ�܂܂ꂽ�_�ł���B����ɂ��AChatGPT���������킹�Ă��Ȃ��m�����Y�t���ꂽ�����ɂ��t�����ꂽ���Ƃ�������B
�@�܂���҂̌��ʂł͐��m�Ƀh�L�������g�̐��l��ǂݎ��A���@��̗e�ʂ̈Ⴂ���������Ƃ��ł����B�Ȃ��u�e�ʁv�ł͂Ȃ��u���@�v�̈Ⴂ�����Ƃ���A���@��́u�S���v���@�ŊԈႢ�����������B����́A�h�L�������g�̕\�`������������Ă��邱�ƂɋN�����Ă���A�ǂݎ�萸�x�̉ۑ�Ƃ�����B����ŁA�h�L�������g���̉ۑ�Ƃ������A�\�`���̐������@����̎��������H�v���邱�ƂŁA�����AI�ł��\���Ȑ��x��S�ۂł���ƍl������B
�@�Ō�ɁAChatGPT�́uGPTs�v�@�\��p���āA���n�艤�^�y�я��^�̈ێ��Ǘ��v�̏��̒m�����������`���b�g�{�b�g�u�j�b�R�[��GPT�v���e�X�g�쐬�����̂ŁA����������l�͈ȉ���URL��������QR�R�[�h�i�}3�j�ɃA�N�Z�X�̏�A�m�F���Ă������������B
|
|
�R�D�摜�F��AI�ɂ���
�i1�j�T�v�Ǝ��
�@�摜�F��AI�́A�R���s���[�^�r�W�����̈ꕪ��ł���A�摜�f�[�^����͂��ē���̃^�X�N�𐋍s����Z�p�ł���B���̕���ɂ́A�摜���ށA���̌��o�A�Z�O�����e�[�V�����A�摜�����A�摜�L���v�V���������A�摜�����A�摜���𑜁A�X�^�C���]���ȂǁA���܂��܂ȃ^�X�N���܂܂��B���ꂼ��̃^�X�N�͈قȂ�Z�p�I�A�v���[�`��K�v�Ƃ��A�قȂ鉞�p����ŗ��p����Ă���B
a) �摜����
�@�摜���ނ́A�^����ꂽ�摜�����炩���ߒ�`���ꂽ�J�e�S���̂����ꂩ�ɕ��ނ���^�X�N�ł���B�Ⴆ�A�����̉摜�����A�L�A���̂����ꂩ�ɕ��ނ��邱�Ƃ��T�^�I�ȗ�ł���B���̕���ł́ACNN�i��ݍ��݃j���[�����l�b�g���[�N�j���L���g�p����Ă���AAlexNet 7) ��ResNet 8) �Ƃ������A�[�L�e�N�`������\�I�ł���B���p����Ƃ��ẮA���i���ށA�����Ԃ̃��f�����ʁA��É摜�f�f�Ȃǂ���������B
b) �摜�F��
�@�摜�F���́A�摜���ɑ��݂��镡���̕��̂����o���A���̈ʒu�ƃN���X����肷��^�X�N�ł���B���̂��Ƃɋ��E�{�b�N�X��`�悵�A���̕��̂ł��邩�����x���t������BYOLO (You Only Look Once) t 9) �AFaster R-CNN t 10) �ASSD (Single Shot Multibox Detector)t 11) �Ȃǂ̃��f�����L���p�����Ă���A�����^�]�Ԃ̏�Q�����o�A�Ď��J�����ɂ��s�R�����o�A��F���ȂǂŊ��p����Ă���B
c) �Z�O�����e�[�V����
�@�Z�O�����e�[�V�����ɂ́A�Z�}���e�B�b�N�Z�O�����e�[�V�����ƃC���X�^���X�Z�O�����e�[�V���������݂���B
�@�Z�}���e�B�b�N�Z�O�����e�[�V���� (Semantic Segmentation) �Ƃ́A�摜���̊e�s�N�Z���ɃN���X�����蓖�Ă�^�X�N�ł���A���ׂẴs�N�Z��������̃N���X�ɕ��ނ����BU-Net 12) ��DeepLab 13) �Ȃǂ̃��f�����悭�g�p����A��É摜��͂⎩���^�]�A�摜�ҏW�Ȃǂ̕���Ŋ��p����Ă���B
�@�܂��C���X�^���X�Z�O�����e�[�V���� (Instance Segmentation)�́A�����N���X���ł��قȂ�ʂ̕��̂���ʂ��A�ʂɃZ�O�����g������^�X�N�ł���B�Ⴆ�A�����̎Ԃ��ʂ����摜�ɑ��A���ꂼ��̎Ԃ�ʁX�Ɏ��ʂ���BMask R-CNN 14) �Ȃǂ̃��f�����g�p����A�����^�]��{�b�g�r�W�����ȂǂŊ��p����Ă��� �B
d) �摜����
�@�摜�����́A�j���[�����l�b�g���[�N��p���ĐV���ȉ摜������^�X�N�ł���B�����̉摜�̃X�^�C����͕킵����A�܂������V�����摜���쐬���邱�Ƃ��\�ł���BGAN�i�����G�l�b�g���[�N�j 15) ��Diffusion���f�� 16) ����\�I�ȋZ�p�ł���A�A�[�g������Q�[���J���A�f�W�^���L���A�f�[�^�g���Ȃǂ̉��p������B
e) �摜�L���v�V����
�@�摜�L���v�V���������́A�摜�̓��e�����R����Ő�������L���v�V����������^�X�N�ł���BEncoder-Decoder 17) ���f����Attention�@�\��������g�����X�t�H�[�}�[���f�����g�p����A�����L���v�V���������⎋�o��Q�Ҏx���A�f�W�^���}�[�P�e�B���O�ŗ��p����Ă���B
�i2�jCNN�ɂ���
�@�摜�F��AI�ɂ����āA�ł��d�v�ȋZ�p�̈��CNN�iConvolutional Neural Network�A��ݍ��݃j���[�����l�b�g���[�N�j�ł���B�ȉ��ɁACNN�̋Z�p�I�ϑJ�ƁA���ꂼ��̋Z�p�ۑ���������邽�߂̐i�W���ȒP�Ɏ����B
a) 1980�N: Neocognitron 18)
�@Neocognitron�́A��ݍ��ݑw�ƃv�[�����O�w���������̐l�H�j���[�����l�b�g���[�N�ł���A���o�p�^�[���F���Ɏg�p���ꂽ�B�ʒu��`��̕ϓ��ɑ��Ċ挒�ȔF�����s�����Ƃ��ł��A�l�H�m�\���摜����������ۂ̊�b�ƂȂ����B
b) 1998�N: LeNet 19)
�@LeNet�́A�菑�������F���ɓ����������f���ł���A��ݍ��ݑw�ƃv�[�����O�w��p���ăs�N�Z�����������I�ɏ��������B����ɂ��A�v�Z�R�X�g��}���A�摜�̓��������ʓI�Ɋw�K������@���m�����ꂽ�B
c) 2012�N: AlexNet
�@AlexNet�́AImageNet�R���y�e�B�V�����ő听�������߂�CNN���f���ł���AReLU����������Dropout�����p���邱�Ƃőw��[�����A���\�����コ�����B���ɁA�u���z�������v��u�ߊw�K�v���������A�[�w�l�b�g���[�N�̊w�K���\�ɂ����B
d) 2014�N: VGGNet 20)
�@VGGNet�́A���ɐ[��CNN�A�[�L�e�N�`���ł���A3x3�̏����ȃt�B���^���d�˂邱�Ƃō����x�ȉ摜�F����B�������B����ŁA�v�Z���\�[�X�̏�����傷��Ƃ����V���ȉۑ���������B
e)
2016�N: ResNet
�@ResNet�́u�c���u���b�N�v�����A���ɐ[���l�b�g���[�N�ł��w�K���\�ƂȂ�悤�v���ꂽ�B����ɂ��A�[�w�l�b�g���[�N�ɂ�����u���z�����v��u���z�����v�̖����������A���f���̐[���𑝂��Ă������x���ێ��ł���悤�ɂȂ����B
f) 2016�N: YOLO
�@YOLO�iYou Only Look Once�j�́A���̌��o�Ɋv���������炵��CNN�x�[�X�̃��f���ł���B�]���̕��̌��o���f���́A�摜�S�̂���ɂ킽���ăX�L�������ĕ��̂����o���Ă������AYOLO�͉摜�S�̂���x�ɏ������A���̂̈ʒu�ƃN���X���ɗ\������B���̃A�v���[�`�ɂ��A���A���^�C���ł̕��̌��o���\�ƂȂ�A���x�Ƒ��x�̗�����啝�Ɍ��コ�����B
g) 2017�N: DenseNet 21)
�@DenseNet�́A�e�w�����ׂĂ̑O�̑w����̓����}�b�v�ɃA�N�Z�X�ł���悤�ɐv����A�����ė��p�𑣐i�����B����ɂ��A�v�Z���\�[�X�������I�Ɏg�p���Ȃ���A��菭�Ȃ��p�����[�^�ō����\�����������B
h) 2020�N: Vision Transformer�iViT�j
�@ViT�́A�摜�F���^�X�N��Transformer�A�[�L�e�N�`����K�p�������f���ł���A�摜���p�b�`�ɕ������A���ꂼ���Transformer�ŏ�������B�]����CNN�����Ƃ���O���[�o���Ȉˑ��W�̊w�K���������A���ɑ�K�̓f�[�^�Z�b�g�ŗD�ꂽ���\�����Ă���B
i) ����Ɖۑ�
�@CNN�͈ˑR�Ƃ��ĉ摜�����̎�v�Ȏ�@�Ƃ��čL�����p����Ă��邪�A�ߔN�ł̓g�����X�t�H�[�}�[���f���̑䓪�ɂ��A�]����CNN�ɑ���V���ȃA�v���[�`���͍�����Ă���B���ɁACNN���Ǐ��I�ȓ����𑨂���̂ɗD��Ă������ŁA�O���[�o���Ȉˑ��W�𑨂���̂����ł���_���ۑ�Ƃ��Ďc���Ă���B����́ACNN�ƃg�����X�t�H�[�}�[��g�ݍ��킹���n�C�u���b�h���f����A�V���ȃA�[�L�e�N�`�������������\���������B
�i3�j���摜�ł̕��̌��o�i�o���u���o�j�̌���
�@�摜�F��AI�̓J�����ݔ���ʐ^�f�[�^������Ύ����ł��邱�Ƃ�����ɐ����ƂƂ̑������ǂ��Ƃ�����B����͏��ƊE�ɂ����Ă����l�̂��Ƃ������A�ێ��Ǘ��ʐ^�̉摜���͂�����C���ɂ�����ُ팟�o�A�����̏펞�Ď��ȂǁA�K�p�͈͂͑���ɂ킽��B
�@�܂��A���ƊE�ł́A�Ǘ��Ɩ��̑������l��ɂ��_����Ď��Ɉˑ����Ă���B���̂��߁A��Ƃ̌�������x�̌��オ�ۑ�ƂȂ��Ă���B���ɁA�����̃o���u��@��̏�ԊĎ��ɂ����ẮA�ُ�̑������������߂��邪�A�l��ɂ��_���ł͌��E������BAI�Z�p�A�Ƃ�킯�摜�F���Z�p�̓����́A�����̉ۑ���������A�Ǘ��Ɩ��̎�������x�̌������������\���������B
�@�����Ŗ{�͂ł́A�摜�F���^�X�N�̒��ł����̌��oAI���f����p���āA�摜���̃o���u���o���\���ǂ�������������B����ɂ��AAI�����̗���⌋�ʍl�@�̈ꏕ�ɂȂ�Ɗ���Ă���B
�@�Ȃ��{�͂̎����f�[�^�̓y�[�W�̊W�シ�ׂĂ��L�ڂ��邱�Ƃ�������߁A�ȉ���URL��������QR�R�[�h�i�}4�j���Q�Ƃ��Ă������������B
a) AI�����̗���
�@�ȉ��̗����AI��������������B
�@�@AI���f���̑I��
�@�AAI���f���̌��\
�@�B�A�m�e�[�V����
�@�C�t�@�C���`���[�j���O
�@�DAI���f���̕]��
b) AI���f���̑I��
�@�{���ł����PoC (�T�O����)�̉ߒ��ŁA���܂��܂ȃ��f����A�[�L�e�N�`�������s���A�^�X�N�ɍœK�ȃ��f����I�肷��ׂ��ł���B�������A����͊ȕւ̂��߁AYOLO���f�����̗p����B
�@YOLO (You Only Look Once) ���f���́A���̌��o�ɂ����č����������Ɛ��x���ւ�CNN (Convolutional Neural Network) �x�[�X�̃A���S���Y���ł���BYOLO�́A�摜�S�̂���x�ɏ������A���̂̈ʒu�ƃN���X���ɗ\������_�����̕��̌��o���f���ƈقȂ�����ł���B��̓I�ɂ́AYOLO�͉摜���Œ�T�C�Y�̃O���b�h�ɕ������A�e�O���b�h�Z�������̂��܂�ł��邩�ǂ�����\������B
�@�]���̕��̌��o���f���́A�摜���̃X�P�[����̈�ŃX�L�������ĕ��̂����o���邽�߁A�v�Z�R�X�g�������A�������x���x���Ȃ�X�����������B�������AYOLO�͉摜�S�̂���x�ɏ������邽�߁A���A���^�C���ł̌��o���\�ƂȂ�A�����Ƃ�Ď��V�X�e���ȂǁA�����������߂��鉞�p�ɓK���Ă���B
�@YOLO�̑�\�I�ȃo�[�W�����ɂ́AYOLOv3�AYOLOv4�AYOLOv5�A�����čŐV��YOLOv8������A���ꂼ�ꂪ���ǂ��d�ˁA���x�⑬�x�̌��オ�}���Ă���B����̌����ł́A�ŐV��YOLOv8 22) ���g�p���A�����̃o���u���o�����݂�B
c) AI���f���̌��\
�@�܂��AYOLO�ł�ImageNet ��5) �ƌĂ���K�͂ȉ摜�f�[�^�Z�b�g��p�������O�w�K���f�����p�ӂ���Ă���B�����ł́A���̎��O�w�K���f����p���āA���n�艤�^�̃}���z�[������̎ʐ^ (�}5) ����o���u�����o�ł��邩���m�F�����B���ʂƂ��āA���O�w�K���f���ł͏��̃o���u�����o���邱�Ƃ͂ł��Ȃ������B���������Ė{�͂�AI���f���\�z�̃��`�x�[�V�����́A���̊e��o���u�����o�ł���悤�ɂ��邱�Ƃł���B
 |
| �}5�@���n�艤�^�̃}���z�[������̎ʐ^ |
d) �A�m�e�[�V����
�@�O���ŏq�ׂ��悤�ɁAYOLO���f���̎��O�w�K���f�����g�p���Ă����o���u�����o���Ȃ����Ƃ����������B���̂��߁AAI���f���ɏ��o���u���w�K�����邽�߂̃f�[�^���쐬����K�v������B���̂悤�Ɏ��O�̃f�[�^��AI�p�ɉ��H���邱�Ƃ��u�A�m�e�[�V�����v�ƌĂԁB
�@�A�m�e�[�V�����́A�ʏ�A�N���E�h�T�[�r�X��I�[�v���\�[�X�\�t�g�E�F�A�iOSS�j�̃c�[�����g�p���čs����B����́AOSS�T�[�r�X�́uLabel Stu-dio�v���g�p����B�ڍׂȎg�����͌����h�L�������g 23) ���Q�l���ꂽ���B
�@�A�m�e�[�V������Ƃ̊T�v��}6�Ŏ����B�}�̂悤�ɁA���o���������� (����̏ꍇ�͊e��o���u) ���l�p (�o�E���f�B���O�{�b�N�X�Ƃ���) �ň͂ނ����ł��邪�A��K�͂ȃv���W�F�N�g�ł͉��S���A���疇�Ƃ����摜�ɑ��ē�����Ƃ��J��Ԃ��K�v������B���̂��߁A�A�m�e�[�V������Ƃɂ�AI���K�p����A�����ŃT�|�[�g����T�[�r�X������B
 |
| �}6�@Labell Studio���g�����A�m�e�[�V���� |
�@����̃e�X�g�ł́A���n�艤�^�y�я��^�̉摜��p�ӂ��āA8���̃A�m�e�[�V���������{�����B�܂��A�e�o���u�̃��x�����͈ȉ��̒ʂ�ł���B
�@�@valve-grey: �n���h���F���O���[
�@�Avalve-red: �n���h���F����
�@�Bvalve-blue: �n���h���F����
�@�Cvalve-white: �n���h���F����
�@�Dvalve-three: �O���o���u
�@�A�m�e�[�V������A�ݒ肵���摜�ƃo�E���f�B���O�{�b�N�X�̏�f�[�^�Ƃ��ăG�N�X�|�[�g�ł���̂ŁA�����p���Ď����̃t�@�C���`���[�j���O�t���[�ւƐi�ށB
e) �f�[�^�g���E�t�@�C���`���[�j���O
�@�O���ŃA�m�e�[�V������Ƃ����{���A�o�E���f�B���O�{�b�N�X�̏����G�N�X�|�[�g�����B����������A�m�e�[�V���������{�����摜��8���Ə��ʂ̂��߁u�������v�ƌĂ��f�[�^�g�������{����B�u�������v���̂͏��ʃf�[�^�ł�AI�w�K�ɕp�ɂɎg�����@�ŁA�f�[�^�ʂ��s�����Ă��Ă��ĉ����\�������x�ێ��ł��郁���b�g������B
 |
| �}7�@�f�[�^�g���̈�� �i��]�Ȃǁj |
�@����͈ȉ��̃f�[�^�����ɂ��f�[�^�̐����������{�����B�i�T���v���摜�F�}7�j
�@�@���T�C�Y
�@�A�������]
�@�B�V�t�g
�@�C�X�P�[��
�@�D��]
�@�E���x�����_���ύX
�@�ȏ�̏������{�����摜���[���I��500���쐬���A������z�[���h�A�E�g�@�ɂ��w�K�p70%�A���ؗp30%�ɕ����ăt�@�C���`���[�j���O�����{�����B
�@���̌��o���f���̃t�@�C���`���[�j���O�ł́A�\�����ꂽ�o�E���f�B���O�{�b�N�X�Ǝ��ۂ̃o�E���f�B���O�{�b�N�X�Ƃ̊Ԃ̏d�Ȃ��]�����鑹�����Ȃǂŕ]�����A�w�K���i��(�}8)�B
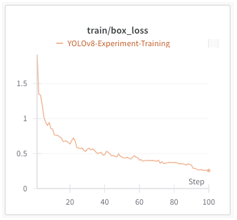 |
| �}8�@�w�K���̑������̐��� |
f) �w�K��AI���f���̕]��
�@�t�@�C���`���[�j���O���I�����o���u���o���f����p���āA���̌��o�̌��ʂ�}9�Ɏ����B�}������ƁA�����̃o���u�����o�ł���悤�ɂȂ������Ƃ��m�F�ł���B
 |
| �}9�@�w�K�ヂ�f���̕��̌��o���� |
�@���̂悤�ɁA���O�w�K���ꂽ���f���ł����Ă��A�A�m�e�[�V�����ƃt�@�C���`���[�j���O���{�����ƂŁA���L�̕��̂����o�ł���悤�ɂ��邱�Ƃ��\�ł���B
�@����ŁA���˂�e�̉e���Ō��o������P�[�X������ꂽ�B���̂悤�Ȗ����������邽�߂ɂ́A����Ȃ�f�[�^�g����قȂ�������ł̊w�K���K�v�ł���ƍl������B�܂��A�o���u�̐F��`��ɉ������t�B���^�����O�Z�p�̓������A���x����Ɋ�^����\��������B
�@�ȏ���AAI�J���̈�A�̗�����ȈՓI�Ɏ��{�����B��ʓI�ɂ́A������PoC���o�Ė{�Ԏ������s���A�^�p���AI���x�̐��ڂ��m�F���Ȃ���A�K�XAI���f���̍X�V�����Ă������Ƃ����߂���B���ɍ���̂悤�ȃo���u���o�̃P�[�X�ł́A���f���̐��x��M�������ێ��E���コ���邽�߂ɁA����I�ȃf�[�^�̒lj���f���̃��g���[�j���O���K�v�ł���B |
|
�S�D��������
�@�{�e�ł́AAI�Z�p�̋}���Ȑi�W�ƁA���̒��ł����ɐ���AI����щ摜�F��AI�̕���ɏœ_�āA���ƊE�ւ̓K�p�\���ɂ��čl�@���s�����BAI�́A�����̋Z�p��⊮���A�]���̎�@�ł͎�������������^�X�N�������I�������x�ɐ��s�����i�Ƃ��āA����܂��܂��d�v�Ȗ������ʂ����Ă����ł��낤�B
�@��̓I�ɂ́A����AI�����p���������f�[�^�̕⊮�A������YOLO��p�����摜�F���ɂ�镨�̌��o�Z�p�ɂ��āA���̎�����@�Ɛ��\�]�����s�����B���O�w�K���ꂽ���f����K�ɃA�m�e�[�V�������A�t�@�C���`���[�j���O���{�����ƂŁA�����̃o���u�̂悤�ȓ���̕��̂������x�Ō��o�ł��邱�Ƃ��m�F�ł����B����́A���ƊE�ɂ�����Ǘ��Ɩ��̎�������������Ɍ������傫�Ȉ���ł���A����̎��p���Ɍ�������b�ƂȂ���̂ł���B
�@�܂��AAI�J���̃v���Z�X�ɂ����ẮA�P�Ȃ�Z�p�̓����ɗ��܂炸�APoC��ʂ������Ɖ^�p��̌p���I�ȃ��f�����P���s���ł��邱�Ƃ����߂ĔF�������B����̌����͂����܂ŊȈՓI�Ȃ��̂ł���A���ۂ̋Ɩ���AI������ۂɂ́A��葽���̃f�[�^��p�����g���[�j���O��A���ω��ւ̑Ή�����܂߂������I�ȃA�v���[�`�����߂���B
�@����̓W�]�Ƃ��ẮAAI�Z�p������ɐi�����A��葽���̋Ɩ��̈�ɐZ�����邱�Ƃ����҂����B���ɁA���ƊE�ɂ����ẮA�摜�F���Z�p�����p�����ݔ��Ǘ��̎�������A����AI�����p�����f�[�^��́A�V�~�����[�V�����Z�p�̔��W�ɂ�邳��Ȃ�������������܂��B�܂��AAI�����ɂ��l��s���̉������Ɛ��x�̌���Ƃ������A����ł̋�̓I�ȃ����b�g�����҂����Ƃ���ł���B
�@�Ō�ɁA�{�e��AI�Z�p�̏��ƊE�ւ̓����Ɍ����������ƂȂ�A����Ȃ錤������؎����̊�b�����Ƃ��Ċ��p����邱�Ƃ�����Ă���B���������A�Z�p�̐i�W�𒍎����A����ł̎����Ɍ��������g�݂�i�߂Ă��������ł���B |
|
NOTES
| ��1�j |
API (Application Programming Interface) �Ƃ́A�\�t�g�E�F�A�Ԃŏ�������肷�邽�߂̃C���^�[�t�F�[�X�̂��ƁBAPI�𗘗p���邱�ƂŁA�قȂ�A�v���P�[�V�����Ԃŋ@�\��f�[�^�����L�E���p���邱�Ƃ��\�ɂȂ�B |
| ��2�j |
�g�[�N���Ƃ́A�e�L�X�g���ׂ������������P�ʂŁAAI���������邽�߂̊�{�I�ȗv�f���w���B |
| ��3�j |
PoC (Proof of Concept) �Ƃ́A�Z�p�̎����\�����m�F���邽�߂̊T�O�����w���B |
| ��4�j |
cos�ގ��x�Ƃ́A�x�N�g���Ԃ̊p�x��p���Ă��̗ގ�����]�������@�ŁA���Ƀe�L�X�g�f�[�^�̗ގ����v�Z�ɗp������B |
| ��5�j |
ImageNet�́A��K�͂ȉ摜�f�[�^�Z�b�g�ł���A���̔F�����f���̎��O�w�K�ɍL���g�p����Ă���B�f�[�^�Z�b�g�ɂ́A�����A�A���A���p�i�A���z���ȂǁA���L���J�e�S���ɕ��ނ��ꂽ���疜���̉摜���܂܂�Ă���B |
|
|
REFERENCES
| 1�j |
OpenAI Developers, https://x.com/OpenAIDevs/status/1813990748406317221 |
| 2�j |
�ߘa6�N�ŏ��ʐM�����Chttps://www.rakuten-card.co.jp/minna-money/topic/article_2305_00063/, 2024�N8��15���A�N�Z�X |
| 3�j |
���؈ꓞ�C���c�a���C�O�����C�������i�FAI�ɂ�鉺�����ǘH�j���\���C�������ʂ̌����鉻�Ȃ�тɃX�g�b�N�}�l�W�����g�C�A�Z�b�g�}�l�W�����g�̍��x���Ɋւ��錤���C��57����{�����w��N��u���W�Cp. 141�C2024. |
| 4�j |
�X����CCordero Jose Andres�C�z��M�ƁC�ɓ����F�F�O���t��ݍ��݃j���[�����l�b�g���[�N�iGCN�FGraph Convolutional Network�j��p�����l�חR���������̃n���|�_�����\�\�����f���̊J���Ɨ\�������̕��́C��57����{�����w��N��u���W�Cp. 179�C2024. |
| 5�j |
������C�����I�C�R��G�j�F�����B�e�摜��͂ɔw�i�����@��p���������ȏ㌟�o�V�X�e���̊J���C��37��S�����Z�p�����W��u���v�|�W�Cpp. 54-57�C2023. |
| 6�j |
“�����E�J�^���O�_�E�����[�h”�C�j�b�R�[������ЁChttps://www.nikko-company.co.jp/watercreation-environment/johkasou/request/, 2024�N8��15���A�N�Z�X |
| 7�j |
Krizhevsky, A., Sutskever, I., & Hinton, G. E.: ImageNet Classification with Deep Convolutional Neural Networks, Advances in Neural Information Processing Systems, 2012. |
| 8�j |
He, K., Zhang, X., Ren, S., & Sun, J.: Deep Residual Learning for Image Recognition, Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2016. |
| 9�j |
Redmon, J., Divvala, S., Girshick, R., & Farhadi, A.: You Only Look Once: Unified, Real-Time Object Detection, Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2016. |
| 10�j |
Ren, S., He, K., Girshick, R., & Sun, J.: Faster R-CNN: Towards Real-Time Object Detection with Region Pro-posal Networks, Advances in Neural Information Pro-cessing Systems, 2015. |
| 11�j |
Liu, W., Anguelov, D., Erhan, D., Szegedy, C., Reed, S., Fu, C. Y., & Berg, A. C.: SSD: Single Shot Multibox De-tector, European Conference on Computer Vision, 2016. |
| 12�j |
Ronneberger, O., Fischer, P., & Brox, T.: U-Net: Convo-lutional Networks for Biomedical Image Segmentation, In-ternational Conference on Medical Image Computing and Computer-Assisted Intervention, 2015. |
| 13�j |
Chen, L. C., Papandreou, G., Kokkinos, I., Murphy, K., & Yuille, A. L.: DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs, arXiv preprint arXiv:1606.00915, 2016. |
| 14�j |
He, K., Gkioxari, G., Dollár, P., & Girshick, R.: Mask R-CNN, Proceedings of the IEEE International Conference on Computer Vision, 2017. |
| 15�j |
Goodfellow, I., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., Courville, A., & Bengio, Y.: Generative Adversarial Nets, Advances in Neural Infor-mation Processing Systems, 2014. |
| 16�j |
Ho, J., Jain, A., & Abbeel, P.: Denoising Diffusion Prob-abilistic Models, Advances in Neural Information Pro-cessing Systems, 2020. |
| 17�j |
Bahdanau, D., Cho, K., & Bengio, Y.: Neural Machine Translation by Jointly Learning to Align and Translate, arXiv preprint arXiv:1409.0473, 2014. |
| 18�j |
Fukushima, K.: Neocognitron: A Self-Organizing Neural Network Model for a Mechanism of Pattern Recognition Unaffected by Shift in Position, Biological Cybernetics, 1980. |
| 19�j |
LeCun, Y., Bottou, L., Bengio, Y., & Haffner, P.: Gradi-ent-Based Learning Applied to Document Recognition, Proceedings of the IEEE, 1998. |
| 20�j |
Simonyan, K., & Zisserman, A.: Very Deep Convolutional Networks for Large-Scale Image Recognition, Proceedings of the International Conference on Learning Representa-tions (ICLR), 2015. |
| 21�j |
Huang, G., Liu, Z., Van Der Maaten, L., & Weinberger, K. Q.: Densely Connected Convolutional Networks, Proceed-ings of the IEEE Conference on Computer Vision and Pat-tern Recognition, 2017. |
| 22�j |
“YOLOv8”, ultralytics, https://docs.ultralytics.com/ja/models/yolov8/, 2024�N8��15���A�N�Z�X |
| 23�j |
Label Studio, https://labelstud.io/, 2024�N8��15���A�N�Z�X |
|
|
Application of Generative AI and Image Recognition AI
in Johkasou Systems |
| |
| Shohei Horikawa |
| |
| This paper examines the potential applications of Generative AI and Image Recognition AI within Johkasou (septic tank) systems. The rapid advancements in AI technology, particularly since 2022, have led to significant improvements in the capabilities of Large Language Models (LLMs) like ChatGPT and multi-modal AI systems. These technologies offer promising applications in various industries, including water treatment and septic system management. This study explores the integration of AI into Johkasou management, with a focus on utilizing image recognition AI for detecting valve components within septic tanks. By applying a YOLO-based object detection model, the research aims to demonstrate the effec-tiveness of AI in automating inspection and monitoring tasks, thereby enhancing operational efficiency and accuracy. The findings suggest that with proper data annotation and model fine-tuning, AI can suc-cessfully detect specific components, despite challenges posed by environmental factors such as lighting and reflection. This paper also outlines the importance of continuous model improvement and the role of data augmentation in maintaining AI performance. The implications for future AI integration in Johka-sou management and other related fields are discussed. |
| |
|
| �i�j�b�R�[�i���j�@IT�\�����[�V�����{���j |
| |
| |
 |
 |
|